Predicting term-deposit subscriptions
A supervised-learning study on the UCI Bank Marketing dataset — which clients of a Portuguese bank will subscribe to a term deposit after a phone campaign?
The problem
Marketing calls are expensive, so the bank wants to focus on the clients most likely to say yes. Framed as binary classification: from a client's profile and campaign history, predict y ∈ {no, yes}.
One field, duration (call length), is dropped: it's only known after the call ends and would leak the outcome — a classic mistake on this dataset. Everything below uses only information available before a call is placed.
Class balance
The target is imbalanced — only about one client in nine subscribes — so we judge models on ROC-AUC and on recall/F1 for the positive class, not raw accuracy (predicting "no" for everyone would already score ~89%).
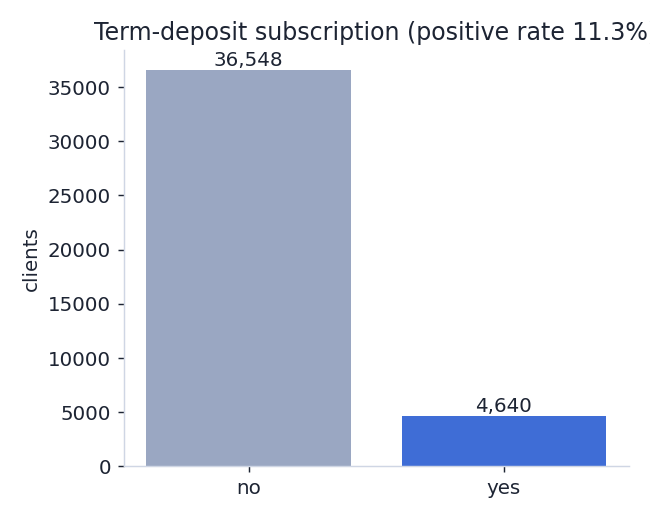
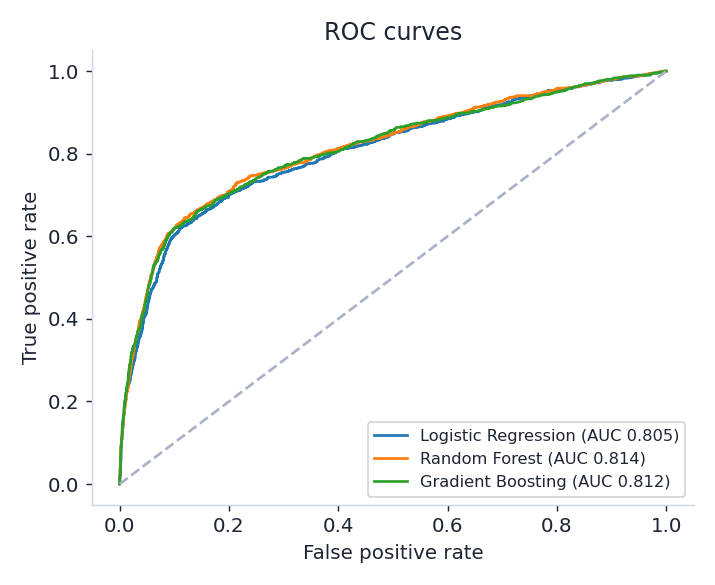
Models & results
Three classifiers share one preprocessing pipeline (standardised numerics + one-hot categoricals), trained on a stratified 75/25 split.
| Model | ROC-AUC | Accuracy | Precision (yes) | Recall (yes) | F1 (yes) |
|---|
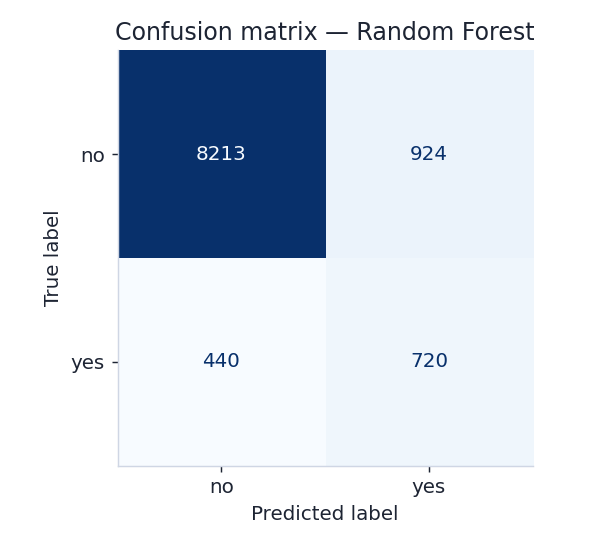
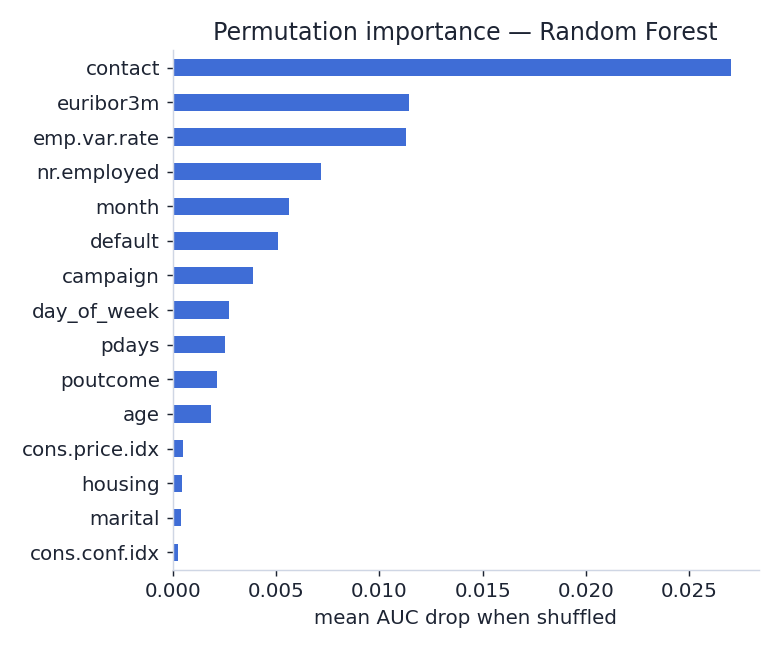
What drives the prediction
Permutation importance (how much test ROC-AUC drops when a feature is shuffled) on the best model. Macro-economic indicators and the timing/outcome of prior contact dominate — not the client's demographics.
Reproduce it
Clone the repo, then pip install -r requirements.txt and python src/train.py to regenerate every figure and the metrics on this page. The walk-through lives in analysis.ipynb.