Real predictions
The trained model, on unseen samples
Each tile is a freshly rendered image (seeds the model never trained on), with the model's actual call and confidence. Generated by predict.py from the trained checkpoint.





train.py.From-Scratch Build · Computer Vision
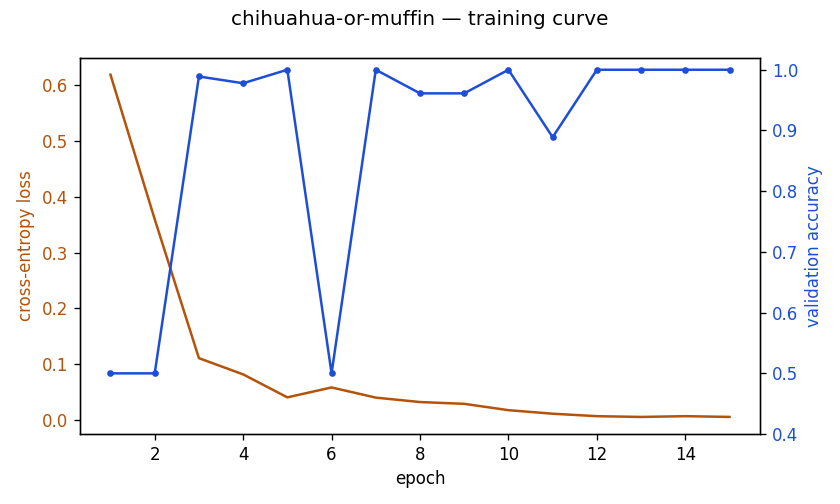
A small convolutional neural network that learns the classic fine-grained vision problem: telling apart two near-identical round-brown-blob classes. Trained end to end on CPU with PyTorch — and it reaches 99.4% accuracy on a held-out test split, against a 50% chance baseline.
Honest note about the data
The famous "chihuahua vs muffin" grid is a set of real internet photos, and that set is unreliable to obtain cleanly. So this project does not use those photos. Instead it ships a procedurally rendered dataset — drawn with numpy and OpenCV — that recreates the difficulty the meme is famous for: both classes are a round tan/brown blob carrying small dark dots, so colour alone gives nothing away and the network must learn structure.
What each image actually is. A 64×64 render. A chihuahua is a brown head-blob with two triangular ears, two symmetric eyes and a nose. A muffin is a brown domed top with a fluted rim and scattered blueberry specks — no ears, no symmetric face. Position, scale, rotation, colour, dot count, lighting and noise are randomised per image, and the two classes have near-identical mean brightness (≈192.7 vs ≈193.4), so the only reliable signal is shape and layout.
Real predictions
Each tile is a freshly rendered image (seeds the model never trained on), with the model's actual call and confidence. Generated by predict.py from the trained checkpoint.
train.py.By the numbers
Architecture
A compact network: three conv → batch-norm → ReLU → max-pool blocks shrink the 64×64 image to 8×8 while growing channels 3→16→32→64, then global average pooling feeds a small dense head to two logits. Trained with Adam, cross-entropy loss and light augmentation (horizontal flip, brightness jitter, noise). Best-on-validation weights are restored before the final test evaluation.
# input 3 x 64 x 64 conv3x3(3 -> 16) + BN + ReLU + maxpool2 # -> 16 x 32 x 32 conv3x3(16 -> 32) + BN + ReLU + maxpool2 # -> 32 x 16 x 16 conv3x3(32 -> 64) + BN + ReLU + maxpool2 # -> 64 x 8 x 8 global average pool # -> 64 dropout -> linear(64->32) -> ReLU -> linear(32->2) # -> 2 logits
Pipeline
data/generate.py renders the two classes into train/val/test folders (70/15/15, class-balanced).
Train-split images get random flips, brightness jitter and noise so the model learns the class, not the pixels.
train.py fits TinyCNN with Adam + cross-entropy, selecting the best epoch on the validation split.
The untouched test split gives the real accuracy and a confusion matrix, written to results.json.
predict.py classifies any single image and returns a label plus class probabilities.