Results
Real numbers on the test split
Measured on the 1,935 held-out test documents — not the training data. The random baseline for five balanced classes is 20%. The two models train on identical TF-IDF features; on this slice the from-scratch Naive Bayes actually edges out logistic regression, a reminder that the classic interpretable approach is hard to beat on bag-of-words text.
| Model | Accuracy | Macro-F1 |
|---|---|---|
| TF-IDF + LogisticRegression | 84.91% | 0.8506 |
| Multinomial Naive Bayes (from scratch) | 87.44% | 0.8758 |
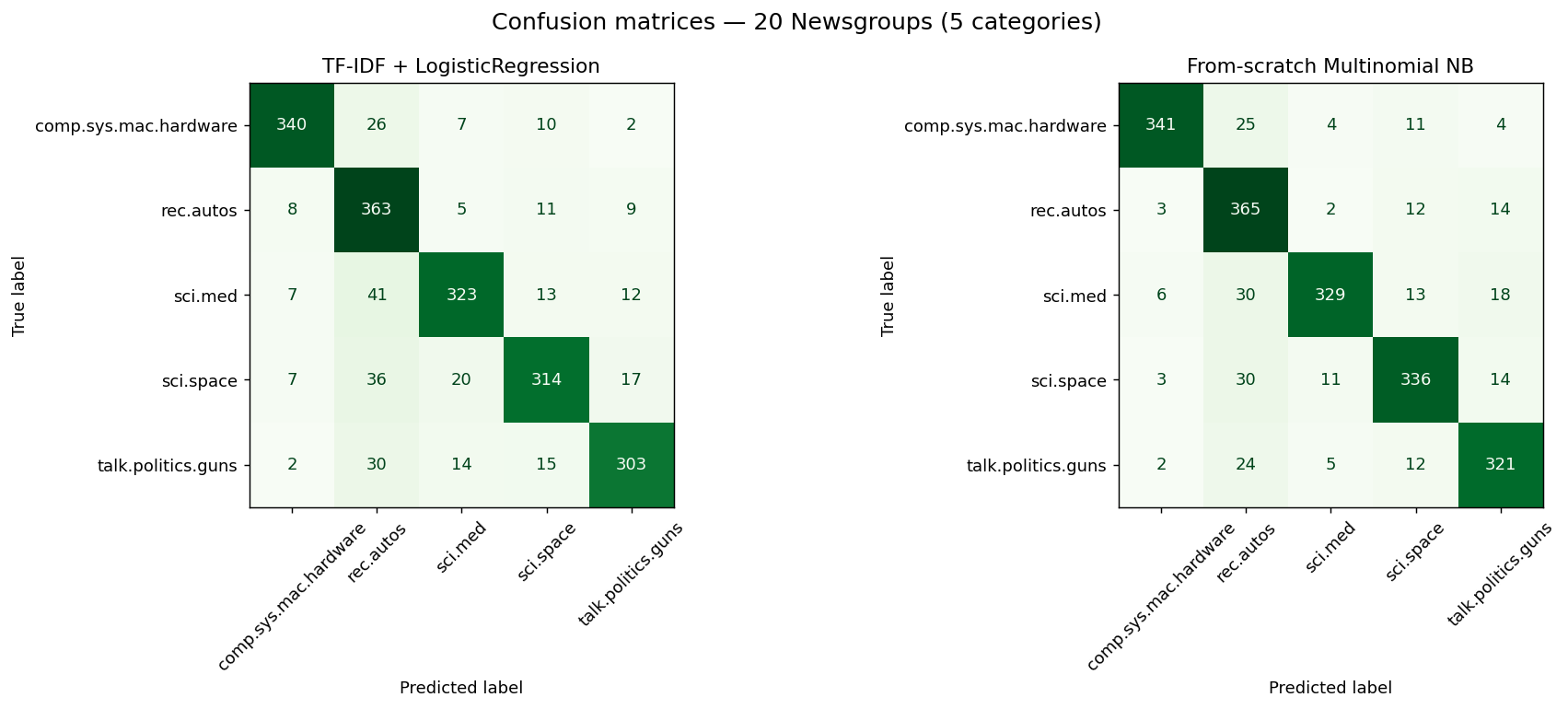
rec.autos ↔ the science groups, where vocabulary overlaps.Reproduce: pip install -r requirements.txt then python train.py. Numbers above are written to results.json by that run; the test suite asserts they clear a sane floor.