effclf
A dataset-agnostic, YAML-driven, multi-pipeline classification framework for tabular data. Declare your experiment — it runs the whole lifecycle.
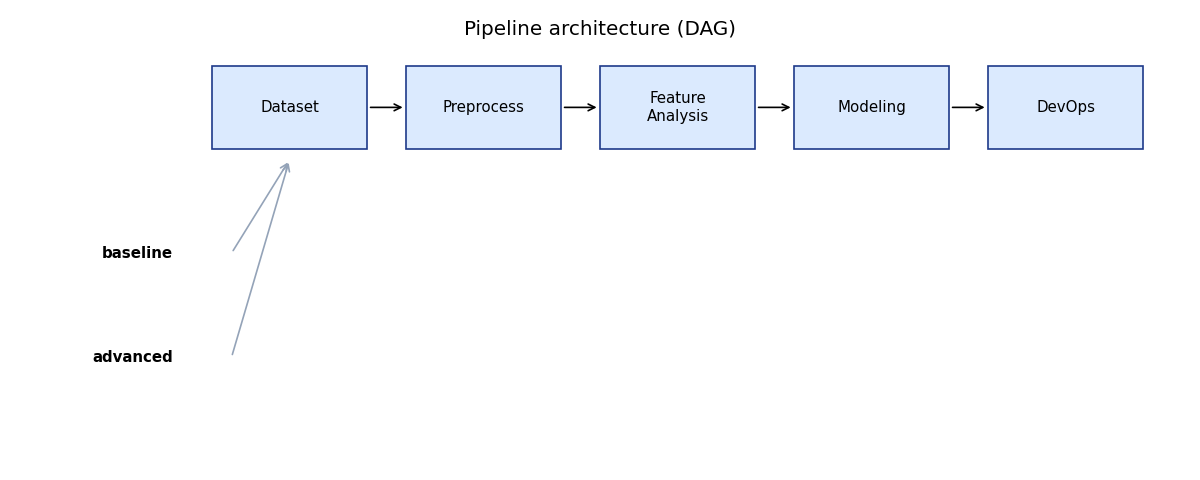
Dataset → Preprocessing → Feature Analysis → Modeling → DevOps
What it does
Declarative
One YAML file is the experiment. Swap datasets or compare pipeline variants without touching code.
Leakage-safe
Every transform fits on train only and replays on test/val — by construction.
Multi-pipeline
Run several pipelines at once with per-pipeline overrides and compare them head-to-head.
Model zoo
Eight models from a majority-class baseline to an MLP, with grid/random search and calibration.
Feature analysis
Low-variance & collinearity pruning, mutual-information ranking, PCA, and L1 selection.
DevOps built in
Results CSV, confusion matrices, comparison charts, a pipeline DAG, and Slack notifications.
30 seconds to a result
pip install -e ".[dev]"
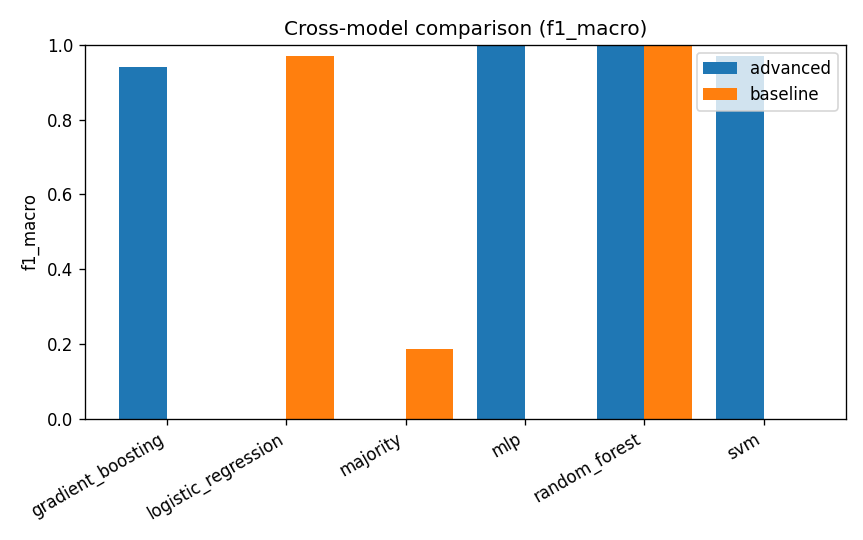
effclf run configurations.yaml=== Best model per pipeline ===
baseline: random_forest (f1_macro = 1.0)
advanced: random_forest (f1_macro = 1.0)Artifacts, automatically