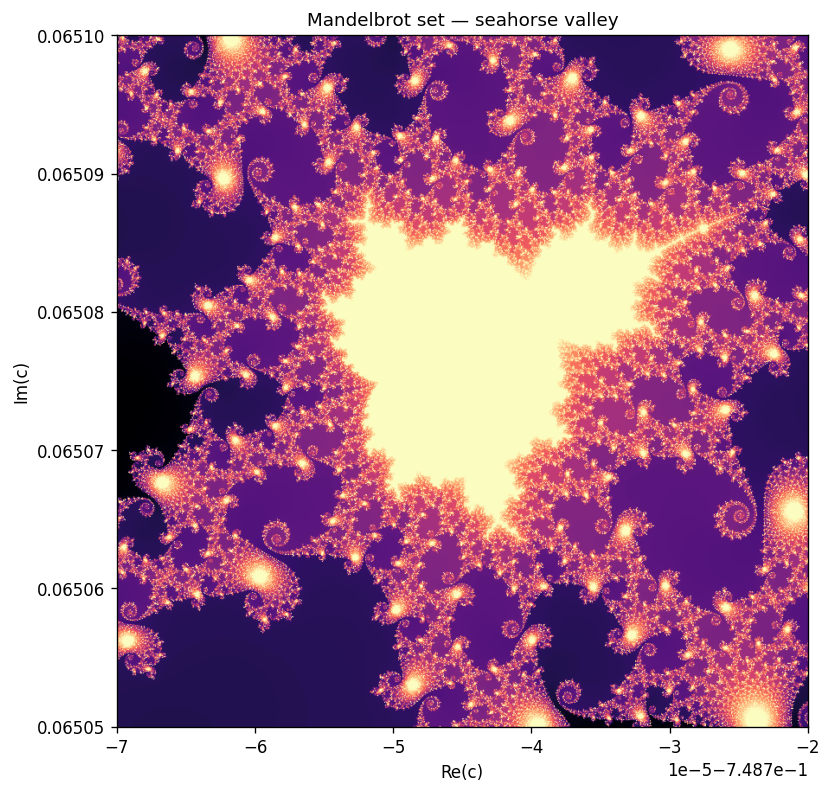
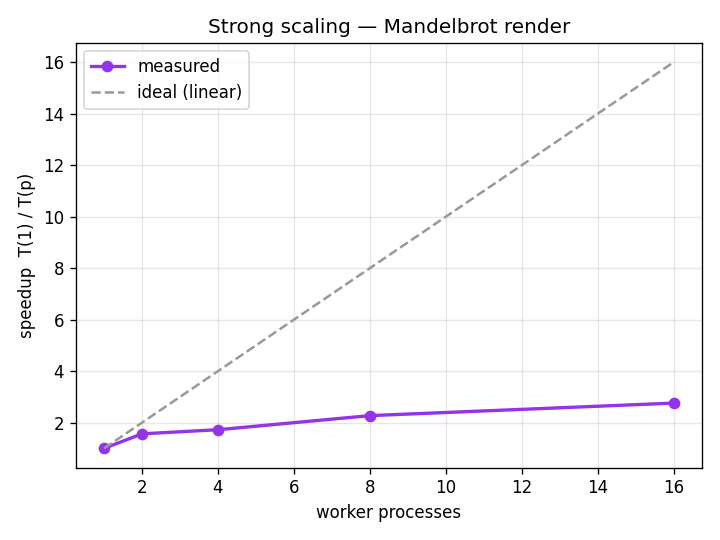
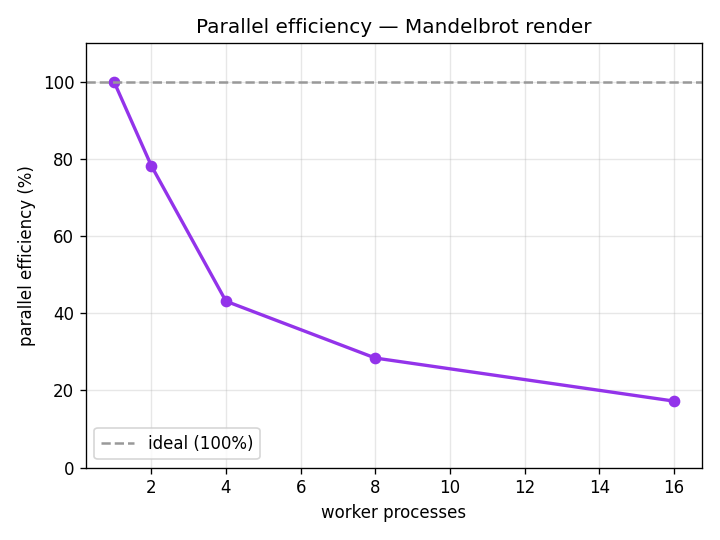
The output
What it computes
For every pixel c of a complex-plane grid, iterate z → z² + c until |z| > 2 and record how many steps it took. That iteration count is the image. The workload is embarrassingly parallel — pixels are independent — but the per-pixel cost is wildly uneven (points inside the set run the full budget), which is what makes the scaling honest rather than trivially linear.